
Building effective macro trading signals requires handling complexity—economic relationships are rarely linear or intuitive. In recent years, machine learning has introduced a new dimension to the quantitative toolbox, offering ways to model these complexities with minimal assumptions. One standout technique among them is random forest regression, a method well-suited for navigating multi-dimensional, nonlinear patterns. This post explores how random forests can be applied to macro signal generation and why they often outperform traditional approaches in this domain.
Why Random Forests Matter in Macro Signal Construction
Random forest regression stands out because it balances model complexity and generalization effectively. Unlike linear models, which assume a straight-line relationship between inputs and outputs, random forests are capable of modeling nonlinear and even non-monotonic patterns—common in macroeconomic data. They work by aggregating predictions from many decision trees, each trained on different data samples and feature subsets. This ensemble approach mitigates the risk of overfitting while capturing deeper interactions in the data.
In macro trading, where theoretical frameworks may not clearly define how variables should relate to returns, such flexibility is invaluable. The forest structure enables robust predictions without needing a predefined economic theory for guidance.
From Theory to Practice: How the Process Works
Let’s break down the implementation. The process typically begins with a structured panel of macroeconomic indicators and lagged asset returns across multiple countries and sectors. A learning pipeline is then used to select and train models over time. In Python, the RandomForestRegressor from scikit-learn is a go-to choice, offering control over tree depth, sample diversity, and feature selection.
Hyperparameter tuning, crucial for managing the trade-off between bias and variance, focuses on aspects like tree size (min_samples_leaf) and data diversity (max_samples, max_features). Notably, forests don’t require exhaustive hyperparameter searches—their strength lies more in ensemble averaging than individual tree perfection.
A Real-World Application: Sector Rotation with Macro Inputs
To demonstrate the value of this approach, a study applied random forest regression to predict sector-level equity returns using over 50 macroeconomic categories drawn from the JPMaQS data system. These indicators reflect point-in-time economic conditions and are organized into themes like growth, inflation, external balance, and more. The strategy targeted relative returns—sector performance versus the overall market—across 11 sectors in 12 developed markets, updated monthly over a 25-year period.
The model pipeline processed expanding data panels sequentially. Each month, a new forest was trained using all available data up to that point. Validation was conducted using a recency-weighted split, focusing on the most recent six months to ensure signals remained timely and adaptive.
The results? Random forest-based signals demonstrated meaningful predictive power. Panel regression tests revealed statistically significant relationships between signal variations and future returns across nearly all sectors. For six sectors, the probability of a true signal was above 90%.
Measuring Value: Beyond Accuracy to Economic Performance
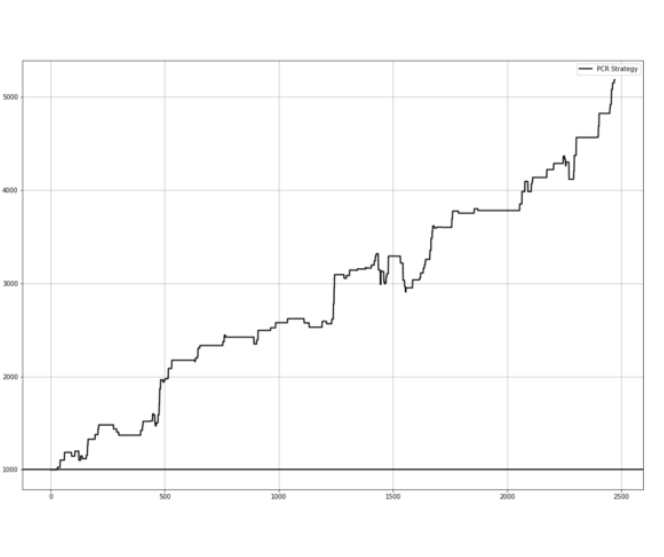
The predictive strength of a model is just one side of the coin. For traders, what matters is economic value. To assess this, the signals were translated into naïve long-short positions across sectors, rebalanced monthly. Even without risk management overlays, the strategy delivered a Sharpe ratio of 1.3 and a Sortino ratio of 1.8 since 2003—impressive figures for a rules-based approach.
Crucially, the strategy’s returns showed low correlation with the S&P 500, highlighting its potential as a diversifying component. Drawdowns were manageable, and performance wasn’t overly reliant on a few strong months—a common issue in many quant strategies.
When compared to a similar approach using linear regression, the forest-based model consistently outperformed. It delivered higher risk-adjusted returns with less seasonal distortion, reinforcing the advantage of capturing nonlinear dynamics in complex economic systems.
Sector-Level Insights
At the individual sector level, cumulative PnLs were positive across the board. Sectors like real estate and IT delivered the highest Sharpe ratios, while even consumer staples—often hard to time—produced modest gains. Importantly, the model identified a wide range of macro indicators as influential, reflecting varied economic drivers across sectors and countries. This diversity is a hallmark of random forests, which weigh feature importance based on their contribution to reducing prediction error.
Final Thoughts
Random forests offer a compelling alternative to linear models for building macro trading signals. Their ability to uncover intricate patterns without overfitting makes them well-suited to the unpredictability of global markets. As this case study shows, when applied with care and supported by robust data, they can enhance both the accuracy and profitability of systematic trading strategies.
In an era where macroeconomic signals are both more available and more complex, embracing advanced learning techniques like random forests isn’t just an option—it’s becoming a necessity for forward-thinking asset managers.